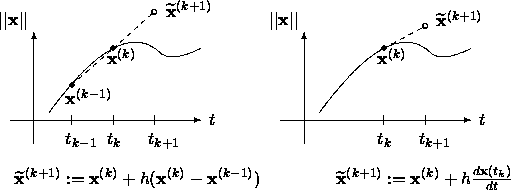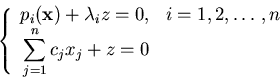Homotopy continuation methods operate in two stages.
Firstly, homotopy methods exploit the structure of P to find a root count
and to construct a start system
![]() that has exactly as many regular solutions as the root count.
This start system is embedded in the homotopy
that has exactly as many regular solutions as the root count.
This start system is embedded in the homotopy
The good properties we expect from a homotopy
![]() are (borrowed from [64]):
are (borrowed from [64]):
Continuation or path-following methods are standard numerical techniques ([3,4,5], [71], [123,125]) to trace the solution paths defined by the homotopy using predictor-corrector methods. The smoothness property of complex polynomial homotopies implies that paths never turn back, so that during correction the parameter t stays fixed, which simplifies the set up of path trackers. A pseudo-code description of a path tracker is in Algorithm 3.1.
The predictor delivers at each step of the method a new value for the continuation parameter and predicts an approximate solution of the corresponding new system in the homotopy. Figure 3 shows two common predictor schemes. The predicted approximate solution is adjusted by applying Newton's method as corrector. The third ingredient in path-following methods is the adaptive step size control. The step length is determined to enforce quadratic convergence in the corrector to avoid path crossing.
| Input:
|
homotopy and start solution | |
|
|
accuracy and upper bounds | |
| Output: |
approximate solution if success | |
| t := 0; k := 0; | initialization | |
|
|
step length | |
|
|
back up values for t and |
|
|
|
previous approximate solution | |
| stop := false; | combines stopping criteria | |
| while t < 1 and not stop loop | ||
|
|
secant predictor for t | |
|
|
secant predictor for |
|
| Newton(
|
correct with Newton's method | |
| if success | step size control | |
| then
|
enlarge step length | |
|
|
go further along path | |
|
|
new back up values | |
| else h := Shrink(h); | reduce step length | |
|
|
step back and try again | |
| end if; | ||
| k := k+1; | augment counter | |
| stop := (
|
stopping criteria | |
| end loop; | ||
| success := (
|
report success or failure |
Following all paths can be done sequentially, one path at a time, or in parallel, with for each solution path the same sequence of values of the continuation parameter. The sequential path-following method has the advantage that the low overhead of communication [6] makes it very suitable to run on multi-processor environments. Note that the memory requirements are optimal.
To solve repeatedly a polynomial system with the same coefficient structure
![]() ,
the homotopy (7) is applied
with
,
the homotopy (7) is applied
with
![]() a system with random
coefficients
a system with random
coefficients ![]() .
Solving
.
Solving
![]() is no longer trivial,
so the name cheater's homotopy [57] is appropriate.
A similar idea appeared in [75,76].
For coefficients given as functions of parameters, a refined version of
cheater's homotopy in [59] avoids repeated evaluation of those
functions during path following:
is no longer trivial,
so the name cheater's homotopy [57] is appropriate.
A similar idea appeared in [75,76].
For coefficients given as functions of parameters, a refined version of
cheater's homotopy in [59] avoids repeated evaluation of those
functions during path following:
Typically, when using a cheater's homotopy, the computational effort spent towards the end of the paths often accounts for most of the work. The main numerical problem is then to distinguish irrelevant solutions at infinity from ill-conditioned but possibly meaningful solutions. End games [43], [77,78,79], [95] provide several procedures to approximate the winding number of a path. Recently, Zeuthen's rule was applied in [50] to determine numerically the multiplicity of an isolated solution. Multi-precision facilities are useful for evaluation of residuals and root refinement for badly scaled solutions.
In most applications, the polynomial systems have real coefficients and invite the use of real homotopies. In [11] it was conjectured and proven in [60] that generically, real homotopies contain no singular points other than a finite number of quadratic turning points. At those bifurcation points pairs of real solution paths become imaginary or conversely, complex conjugated solution paths join to yield two real solution paths. We refer to [2], [38], [64] and [60,61] for a discussion of numerical techniques to deal with quadratic turning points. A remarkable application of real homotopies in the real world consists in the finding of the relevant parameters of a polynomial system to maximize the number of real roots, see [18] for the 40 real solutions for the Stewart-Gough platform in mechanics.
In [93] the use of homotopy continuation to deal with overdetermined and components of solutions is discussed. Geometrically one slices the components of solutions with as many random hyperplanes as the dimension of the components. The solutions to the original polynomial system augmented with these random linear equations for the hyperplanes are generic points of the components, constituting the main numerical data to study those components. In particular, the number of generic points one obtains by this slicing procedure equals the sum of the degrees over all top-dimensional components of solutions.
To make the algorithms of [93] more efficient, in [94],
the following embedding of the polynomial system
![]() is proposed:
is proposed:
The embedding (9) is performed repeatedly in the routine `Embed' in the algorithm (copied from [94]) below.
| Input: P, n. | system with solutions in
|
|||
| Output:
|
embeddings with solutions | |||
|
|
initialize embedding sequence | |||
| for i from 1 up to n do | slice and embed | |||
|
|
zi = new added variable | |||
| end for; | homotopy sequence starts | |||
|
|
all roots are isolated, nonsingular, with
|
|||
| for i from n-1 down to 0 do | countdown of dimensions | |||
Hi+1 :=
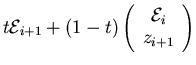 ; ; |
|
|||
|
|
||||
| as |
on component | |||
|
|
not on component: these solutions | |||
| are isolated and nonsingular | ||||
| end for. |
This embedding allows the efficient treatment of overdetermined systems and other nonproper intersections. By perturbing the added hyperplanes and extending the generic points by continuation, interpolation methods can lead to equations for the components.